Ronghang Hu, Amanpreet Singh
Abstract
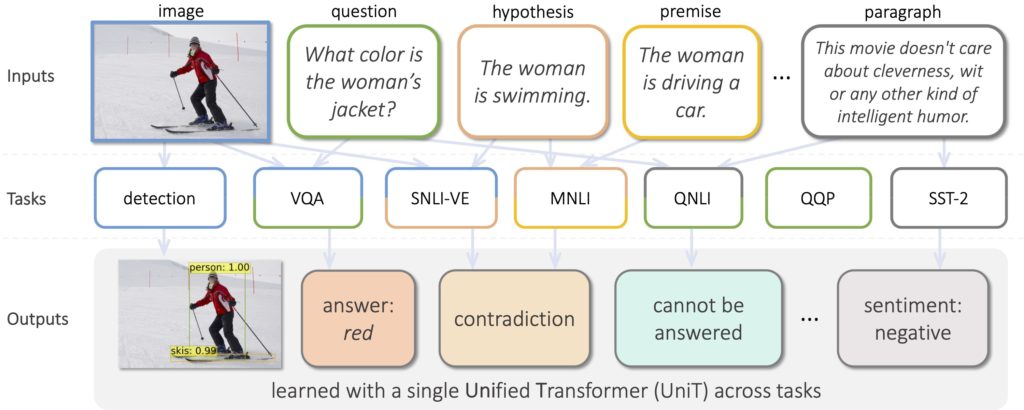
We propose UniT, a Unified Transformer model to simultaneously learn the most prominent tasks across different domains, ranging from object detection to natural language understanding and multimodal reasoning. Based on the transformer encoder-decoder architecture, our UniT model encodes each input modality with an encoder and makes predictions on each task with a shared decoder over the encoded input representations, followed by task-specific output heads. The entire model is jointly trained end-to-end with losses from each task. Compared to previous efforts on multi-task learning with transformers, we share the same model parameters across all tasks instead of separately fine-tuning task-specific models and handle a much higher variety of tasks across different domains. In our experiments, we learn 7 tasks jointly over 8 datasets, achieving strong performance on each task with 87.5% fewer parameters.
Publications
- R. Hu, A. Singh. UniT: Multimodal Multitask Learning with a Unified Transformer. arXiv preprint arXiv:2102.10772, 2021.
(PDF)
@article{hu2021unit,
title={UniT: Multimodal multitask learning with a unified transformer},
author={Hu, Ronghang and Singh, Amanpreet},
journal={arXiv preprint arXiv:2102.10772},
year={2021}
}
Code
- code will be released in MMF