Recent projects
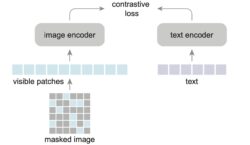 Scaling Language-Image Pre-training via Masking
Scaling Language-Image Pre-training via Masking
Y. Li*, H. Fan*, R. Hu*, C. Feichtenhofer†, K. He† (*: equal technical contribution, †: equal advising)
Computer Vision and Pattern Recognition (CVPR), 2023
(PDF, Code)
- We present Fast Language-Image Pre-training (FLIP), which gives ~3.7x speedup over the traditional CLIP and improves accuracy under the same training data on a large variety of downstream tasks.
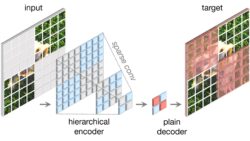 ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, S. Xie.
Computer Vision and Pattern Recognition (CVPR), 2023
(PDF, Code)
- We propose a fully convolutional masked autoencoder framework (FCMAE) and a new Global Response Normalization (GRN) layer that can be added to the ConvNeXt architecture to enhance inter-channel feature competition.
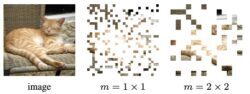 Exploring Long-Sequence Masked Autoencoders
Exploring Long-Sequence Masked Autoencoders
R. Hu, S. Debnath, S. Xie, X. Chen
arXiv preprint arXiv:2210.07224, 2022
(PDF, Code)
- We show that masked autoencoders scale well with pre-training sequence length, especially when transferring to object detection and semantic segmentation.
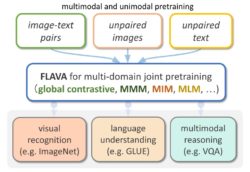 FLAVA: A Foundational Language And Vision Alignment Model
FLAVA: A Foundational Language And Vision Alignment Model
A. Singh*, R. Hu*, V. Goswami*, G. Couairon, W. Galuba, M. Rohrbach, D. Kiela (*: equal contribution)
Computer Vision and Pattern Recognition (CVPR), 2022
(PDF, Project Page)
- We propose the FLAVA model that performs well over a wide variety of 35 tasks on all three target modalities: 1) vision, 2) language, and 3) vision & language, and develop an efficient joint pretraining approach on both unimodal sources.
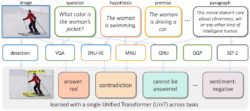 UniT: Multimodal Multitask Learning with a Unified Transformer
UniT: Multimodal Multitask Learning with a Unified Transformer
R. Hu, A. Singh
International Conference on Computer Vision (ICCV), 2021
(PDF, Project Page)
- We build UniT, a unified transformer encoder-decoder model to simultaneously learn the most prominent tasks across different domains, ranging from object detection to language understanding and multimodal reasoning.
 Worldsheet: Wrapping the World in a 3D Sheet for View Synthesis from a Single Image
Worldsheet: Wrapping the World in a 3D Sheet for View Synthesis from a Single Image
R. Hu, N. Ravi, A. Berg, D. Pathak
International Conference on Computer Vision (ICCV), 2021
(PDF, Project Page)
- Worldsheet synthesizes novel views of a scene from a single image using a mesh sheet for scene representation, by warping a grid sheet onto the scene geometry via grid offset and depth.
 TextCaps: a Dataset for Image Captioning with Reading Comprehension
TextCaps: a Dataset for Image Captioning with Reading Comprehension
O. Sidorov, R. Hu, M. Rohrbach, A. Singh
European Conference on Computer Vision (ECCV), 2020
(PDF, Dataset and Challenge)
- TextCaps requires models to read and reason about text in images to generate captions about them. Specifically, models need to incorporate a new modality of text present in the images and reason over it and visual content in the image to generate image descriptions.
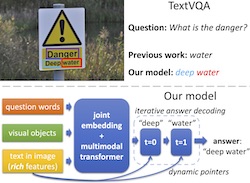 Iterative Answer Prediction with Pointer-Augmented Multimodal Transformers for TextVQA
Iterative Answer Prediction with Pointer-Augmented Multimodal Transformers for TextVQA
R. Hu, A. Singh, T. Darrell, M. Rohrbach
Computer Vision and Pattern Recognition (CVPR), 2020
(PDF, Project Page)
- We propose a novel model for the TextVQA task based on a multimodal transformer architecture with iterative answer prediction and rich feature representations for OCR tokens, largely outperforming previous work on three datasets.
Previous projects
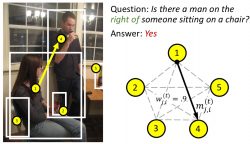 Language-Conditioned Graph Networks for Relational Reasoning
Language-Conditioned Graph Networks for Relational Reasoning
R. Hu, A. Rohrbach, T. Darrell, K. Saenko
International Conference on Computer Vision (ICCV), 2019
(PDF, Project Page)
- To support grounded language reasoning tasks such as VQA and REF, we propose Language-Conditioned Graph Networks (LCGN) to build contextualized representations for objects in a visual scene through iterative message passing conditioned on the textual input.
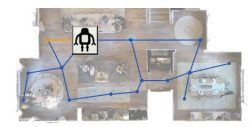 Are You Looking? Grounding to Multiple Modalities in Vision-and-Language Navigation
Are You Looking? Grounding to Multiple Modalities in Vision-and-Language Navigation
R. Hu, D. Fried, A. Rohrbach, D. Klein, T. Darrell, K. Saenko
Annual Meeting of the Association for Computational Linguistics (ACL), 2019
(PDF)
- Do recent vision-and-language navigation models effectively use visual inputs? We find that they often don't — visual features may even hurt them. To address this problem, we propose to decompose the grounding procedure into a set of expert models with access to different modalities.
 Speaker-Follower Models for Vision-and-Language Navigation
Speaker-Follower Models for Vision-and-Language Navigation
D. Fried*, R. Hu*, V. Cirik*, A. Rohrbach, J. Andreas, L.-P. Morency, T. Berg-Kirkpatrick, K. Saenko, D. Klein**, T. Darrell** (*, **: equal contribution)
Neural Information Processing Systems (NeurIPS), 2018
(PDF, Project Page)
- We address vision-and-language navigation with the help from a speaker model to synthesize new instructions for data augmentation and to implement pragmatic reasoning, both supported by a panoramic action space that reflects the granularity of human-generated instructions.
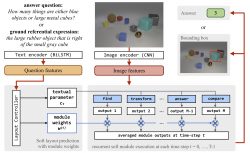 Explainable Neural Computation via Stack Neural Module Networks
Explainable Neural Computation via Stack Neural Module Networks
R. Hu, J. Andreas, T. Darrell, K. Saenko
European Conference on Computer Vision (ECCV), 2018
(PDF, Project Page)
- We present a novel neural modular approach that performs compositional reasoning by automatically inducing a desired sub-task decomposition without relying on strong supervision, being fully differentiable and more interpretable to human evaluators.
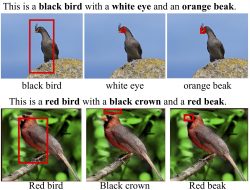 Grounding Visual Explanations
Grounding Visual Explanations
L. A. Hendricks, R. Hu, T. Darrell, Z. Akata
European Conference on Computer Vision (ECCV), 2018
(PDF)
- We propose a phrase-critic model to refine generated candidate explanations. Our explainable AI agent is capable of providing counter arguments for an alternative prediction, i.e. counterfactuals, along with explanations that justify the correct classification decisions.
 Learning to Segment Every Thing
Learning to Segment Every Thing
R. Hu, P. Dollár, K. He, T. Darrell, R. Girshick
Computer Vision and Pattern Recognition (CVPR), 2018
(PDF, Project Page)
- We propose a new partially supervised training paradigm, together with a novel weight transfer function, that enables training instance segmentation models over a large set of thousands of categories with box annotations, but only a small fraction have mask annotations.
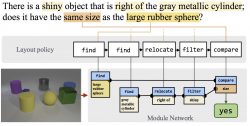 Learning to Reason: End-to-End Module Networks for Visual Question Answering
Learning to Reason: End-to-End Module Networks for Visual Question Answering
R. Hu, J. Andreas, M. Rohrbach, T. Darrell, K. Saenko
International Conference on Computer Vision (ICCV), 2017
(PDF, Project Page)
- We propose End-to-End Module Networks (N2NMNs) for visual question answering, which learns to reason by directly predicting instance-specific network layouts without the aid of a parser. Our model learns to generate network structures while simultaneously learning network parameters (using the downstream task loss).
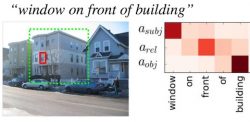 Modeling Relationships in Referential Expressions with Compositional Modular Networks
Modeling Relationships in Referential Expressions with Compositional Modular Networks
R. Hu, M. Rohrbach, J. Andreas, T. Darrell, K. Saenko
Computer Vision and Pattern Recognition (CVPR), 2017
(PDF, Project Page)
- We propose Compositional Modular Networks (CMNs) for handling relationships in natural language referential expressions, which explicitly models the compositional linguistic structure of referential expressions and their groundings, and incorporates two types of modules that consider a region's local features and pairwise interaction between regions.
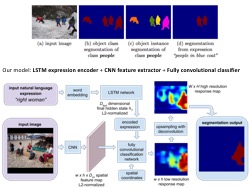 Segmentation from Natural Language Expressions
Segmentation from Natural Language Expressions
R. Hu, M. Rohrbach, T. Darrell
European Conference on Computer Vision (ECCV), 2016
(PDF, Project Page)
- We address the challenging problem of generating a pixelwise segmentation output for the image region described by a natural language referential expression, through a recurrent convolutional neural network model that encodes the expression, extracts a spatial feature map and performs pixelwise classification.
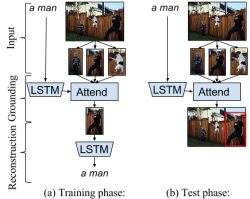 Grounding of Textual Phrases in Images by Reconstruction
Grounding of Textual Phrases in Images by Reconstruction
A. Rohrbach, M. Rohrbach, R. Hu, T. Darrell, B. Schiele
European Conference on Computer Vision (ECCV), 2016
(PDF)
- A novel approach to learn the grounding (localizing) a textual phrase in a description sentence by reconstructing the phrase using an attention mechanism, outperforming prior work which trains with the grounding (bounding box) annotations.
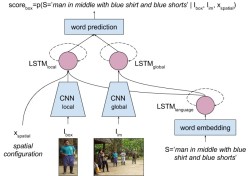 Natural Language Object Retrieval
Natural Language Object Retrieval
R. Hu, H. Xu, M. Rohrbach, J. Feng, K. Saenko, T. Darrell
Computer Vision and Pattern Recognition (CVPR), 2016
(PDF, Project Page)
- We propose Spatial Context Recurrent ConvNet (SCRC) model as scoring function on candidate boxes for object retrieval to localize a target object within a given image based on a natural language query of the object, integrating spatial configurations and global scene-level contextual information into the network.
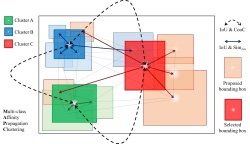 Spatial Semantic Regularisation for Large Scale Object Detection
Spatial Semantic Regularisation for Large Scale Object Detection
D. Mrowca, M. Rohrbach, J. Hoffman, R. Hu, K. Saenko, T. Darrell
International Conference on Computer Vision (ICCV), 2015
(PDF)
- A multi-class spatial regularization method based on adaptive affinity propagation clustering which simultaneously optimizes across all categories and all proposed locations in the image to improve both location and categorization of selected detection proposals.
 LSDA: Large Scale Detection through Adaptation
LSDA: Large Scale Detection through Adaptation
J. Hoffman, S. Guadarrama, E. Tzeng, R. Hu, J. Donahue, R. Girshick, T. Darrell, K. Saenko
Neural Information Processing Systems (NIPS), 2014
(PDF)
- Built an end-to-end real-time ImageNET 7604 category detector using deep convolutional neural network with spatial pyramid pooling, together with window proposal methods. Used domain adaption to transfer a classification network into a detection network. Showed a demo during RSS 2014 and ECCV 2014.
 Robust head-shoulder detection using a two-stage cascade framework
Robust head-shoulder detection using a two-stage cascade framework
R. Hu, R. Wang, S. Shan, X. Chen
International Conference on Pattern Recognition (ICPR), 2014
(PDF)
- We propose a two-stage cascade framework for robust head-shoulder detection, combining the merits of region descriptors of different orders of statistics in a coarse-to-fine structure.