Ronghang Hu, Marcus Rohrbach, Trevor Darrell
Abstract
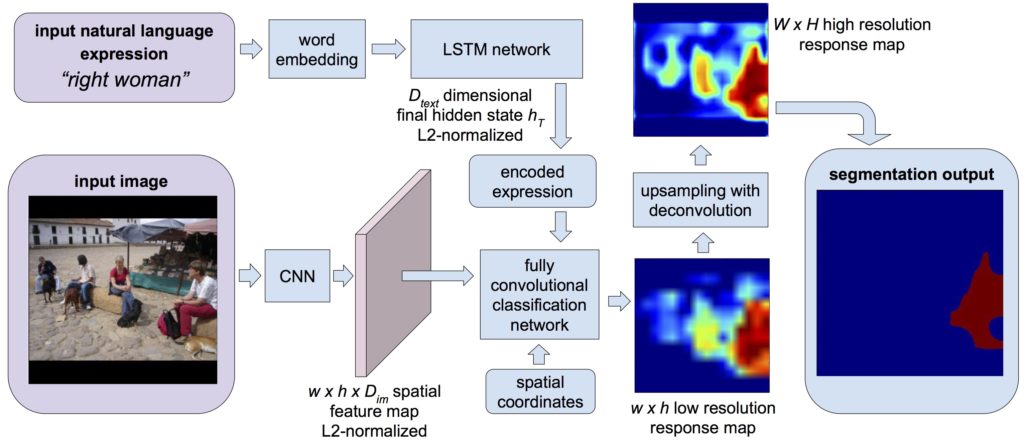
We approach the novel problem of segmenting an image based on a natural language expression. This is different from traditional semantic segmentation over a predefined set of semantic classes, as e.g., the phrase "two men sitting on the right bench" requires segmenting only the two people on the right bench and no one standing or sitting on another bench. Previous approaches suitable for this task were limited to a fixed set of categories and/or rectangular regions. To produce pixelwise segmentation for the language expression, we propose an end-to-end trainable recurrent and convolutional network model that jointly learns to process visual and linguistic information. In our model, a recurrent LSTM network is used to encode the referential expression into a vector representation, and a fully convolutional network is used to a extract a spatial feature map from the image and output a spatial response map for the target object. We demonstrate on a benchmark dataset that our model can produce quality segmentation output from the natural language expression, and outperforms baseline methods by a large margin.
Publications
- R. Hu, M. Rohrbach, T. Darrell, Segmentation from Natural Language Expressions. in ECCV, 2016
(PDF, Slides)
@inproceedings{hu2016segmentation,
title={Segmentation from Natural Language Expressions},
author={Hu, Ronghang and Rohrbach, Marcus and Darrell, Trevor},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2016}
}
Data
- The training, validation and test split of ReferIt dataset used in our experiments can be downloaded here.