Ronghang Hu, Huazhe Xu, Marcus Rohrbach, Jiashi Feng, Kate Saenko, Trevor Darrell
Abstract
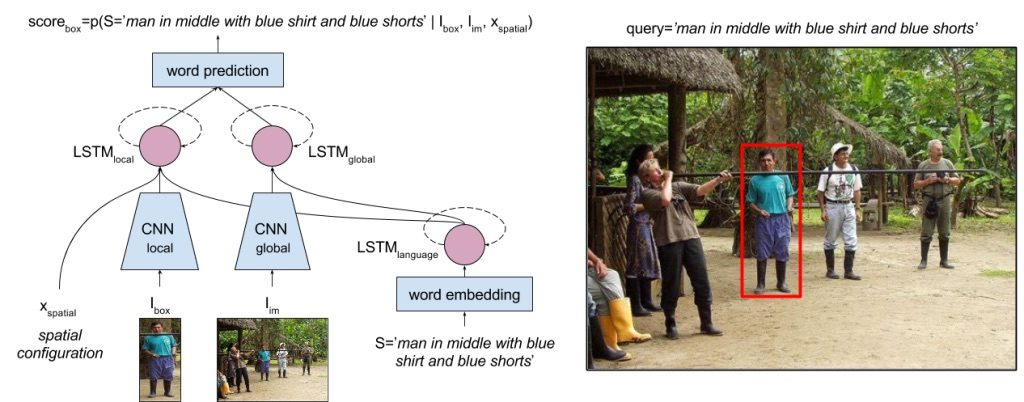
We address the task of natural language object retrieval, to localize a target object within a given image based on a natural language query of the object. Natural language object retrieval differs from text-based image retrieval task as it involves spatial information about objects within the scene and global scene context. To address this issue, we propose a novel Spatial Context Recurrent ConvNet (SCRC) model as scoring function on candidate boxes for object retrieval, integrating spatial configurations and global scene-level contextual information into the network. Our model processes query text, local image descriptors, spatial configurations and global context features through a recurrent network, outputs the probability of the query text conditioned on each candidate box as a score for the box, and can transfer visual-linguistic knowledge from image captioning domain to our task. Experimental results demonstrate that our method effectively utilizes both local and global information, outperforming previous baseline methods significantly on different datasets and scenarios, and can exploit large scale vision and language datasets for knowledge transfer.
Publications
- R. Hu, H. Xu, M. Rohrbach, J. Feng, K. Saenko, T. Darrell, Natural Language Object Retrieval. in CVPR, 2016
(PDF, Slides)
@inproceedings{hu2016natural,
title={Natural Language Object Retrieval},
author={Hu, Ronghang and Xu, Huazhe and Rohrbach, Marcus and Feng, Jiashi and Saenko, Kate and Darrell, Trevor},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2016}
}
Datasets
- The training, validation and test split of ReferIt dataset used in our experiments can be downloaded here.
- 100 top-scoring EdgeBox proposals on ReferIt dataset can be downloaded here (stored as text files per image; each row is a bounding box proposal in
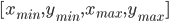 format, 0-indexed; can be loaded with
format, 0-indexed; can be loaded with numpy.loadtxt). - The Kitchen dataset used in our experiment can be downloaded here.
Code
- Code (in Caffe) available at here.