Daniel Fried, Ronghang Hu, Volkan Cirik, Anna Rohrbach, Jacob Andreas, Louis-Philippe Morency, Taylor Berg-Kirkpatrick, Kate Saenko, Dan Klein, Trevor Darrell
Abstract
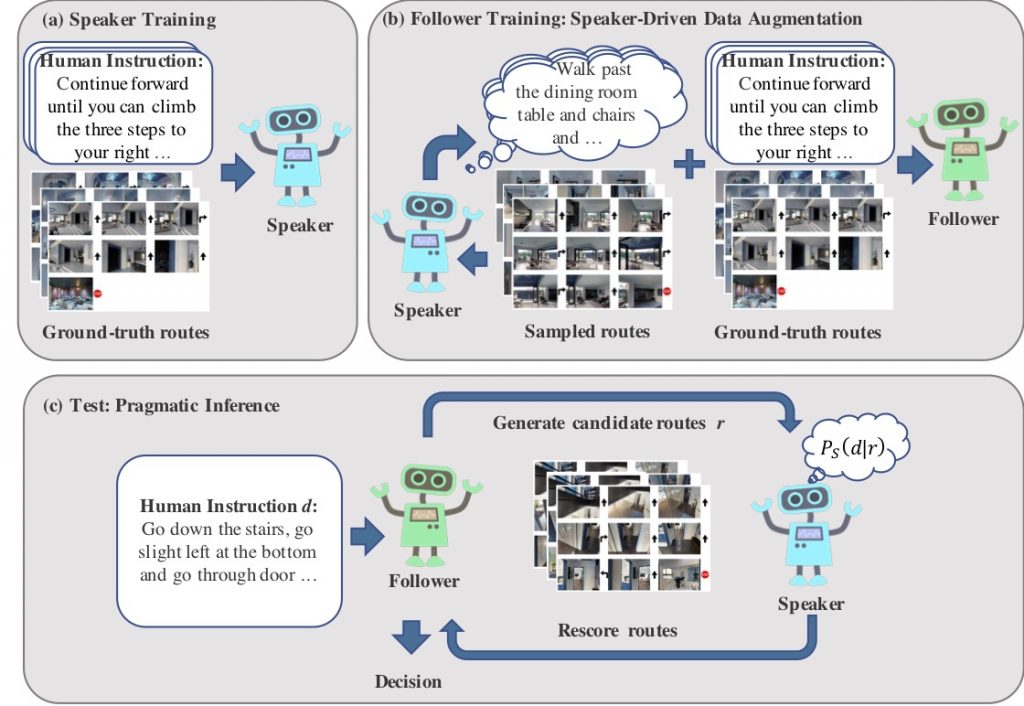
Navigation guided by natural language instructions presents a challenging reasoning problem for instruction followers. Natural language instructions typically identify only a few high-level decisions and landmarks rather than complete low-level motor behaviors; much of the missing information must be inferred based on perceptual context. In machine learning settings, this presents a double challenge: it is difficult to collect enough annotated data to enable learning of this reasoning process from scratch, and empirically difficult to implement the reasoning process using generic sequence models. Here we describe an approach to vision-and-language navigation that addresses both these issues with an embedded speaker model. We use this speaker model to synthesize new instructions for data augmentation and to implement pragmatic reasoning for evaluating candidate action sequences. Both steps are supported by a panoramic action space that reflects the granularity of human-generated instructions. Experiments show that all three pieces of this approach---speaker-driven data augmentation, pragmatic reasoning and panoramic action space---dramatically improve the performance of a baseline instruction follower, more than doubling the success rate over the best existing approach on a standard benchmark.
Publications
- D. Fried*, R. Hu*, V. Cirik*, A. Rohrbach, J. Andreas, L.-P. Morency, T. Berg-Kirkpatrick, K. Saenko, D. Klein**, T. Darrell**, Speaker-Follower Models for Vision-and-Language Navigation. in NeurIPS, 2018 (*, **: indicates equal contribution)
(PDF)
@inproceedings{fried2018speaker,
title={Speaker-Follower Models for Vision-and-Language Navigation},
author={Fried, Daniel and Hu, Ronghang and Cirik, Volkan and Rohrbach, Anna and Andreas, Jacob and Morency, Louis-Philippe and Berg-Kirkpatrick, Taylor and Saenko, Kate and Klein, Dan and Darrell, Trevor},
booktitle={Neural Information Processing Systems (NeurIPS)},
year={2018}
}
Augmented Data on R2R
- If you only want to use our data augmentation on the R2R dataset but don't need our models, you can directly download our augmented data on R2R (JSON file containing synthetic data generated by our speaker model) here. This JSON file is in the same format as the original R2R dataset, with one synthetic instruction per sampled new trajectory. Note that we first trained on the combination of the original and the augmented data, and then fine-tuned on the original training data.
Code
- Code (in PyTorch) available at here.