Ronghang Hu, Jacob Andreas, Marcus Rohrbach, Trevor Darrell, Kate Saenko
Abstract
Natural language questions are inherently compositional, and many are most easily answered by reasoning about their decomposition into modular sub-problems. For example, to answer "is there an equal number of balls and boxes?" we can look for balls, look for boxes, count them, and compare the results. The recently proposed Neural Module Network (NMN) architecture implements this approach to question answering by parsing questions into linguistic substructures and assembling question-specific deep networks from smaller modules that each solve one subtask. However, existing NMN implementations rely on brittle off-the-shelf parsers, and are restricted to the module configurations proposed by these parsers rather than learning them from data. In this paper, we propose End-to-End Module Networks (N2NMNs), which learn to reason by directly predicting instance-specific network layouts without the aid of a parser. Our model learns to generate network structures (by imitating expert demonstrations) while simultaneously learning network parameters (using the downstream task loss). Experimental results on the new CLEVR dataset targeted at compositional question answering show that N2NMNs achieve an error reduction of nearly 50% relative to state-of-the-art attentional approaches, while discovering interpretable network architectures specialized for each question.
Method
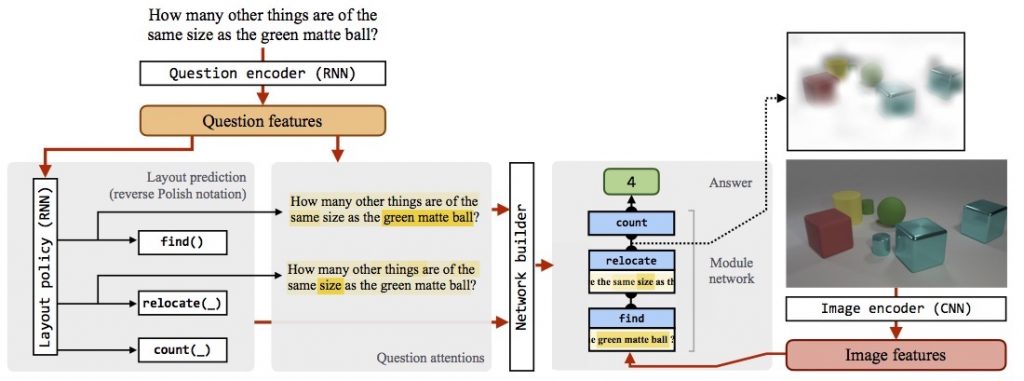
Our N2NMN model consists of two main components: a set of co-attentive neural modules that provide parameterized functions for solving sub-tasks, and a layout policy to predict a question-specific layout from which a neural network is dynamically assembled. Check out the following video for a detailed introduction of our model.
Our model breaks down complex reasoning problems posed in textual questions into a few sub-tasks connected together, and learns to predict a suitable layout expression for each question using our layout policy implemented with a sequence-to-sequence RNN. Different from previous work, we use a new module parameterization that uses a soft attention over question words rather than hard-coded word assignments. During training, the model can be first trained with behavior cloning from an expert layout policy, and further optimized end-to-end using reinforcement learning.
Publications
- R. Hu, J. Andreas, M. Rohrbach, T. Darrell, K. Saenko, Learning to Reason: End-to-End Module Networks for Visual Question Answering. in ICCV, 2017
(PDF)
@inproceedings{hu2017learning,
title={Learning to Reason: End-to-End Module Networks for Visual Question Answering},
author={Hu, Ronghang and Andreas, Jacob and Rohrbach, Marcus and Darrell, Trevor and Saenko, Kate},
booktitle={Proceedings of the IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
Code
- Code (in TensorFlow) available at here.