Ronghang Hu, Marcus Rohrbach, Jacob Andreas, Trevor Darrell, Kate Saenko
Abstract
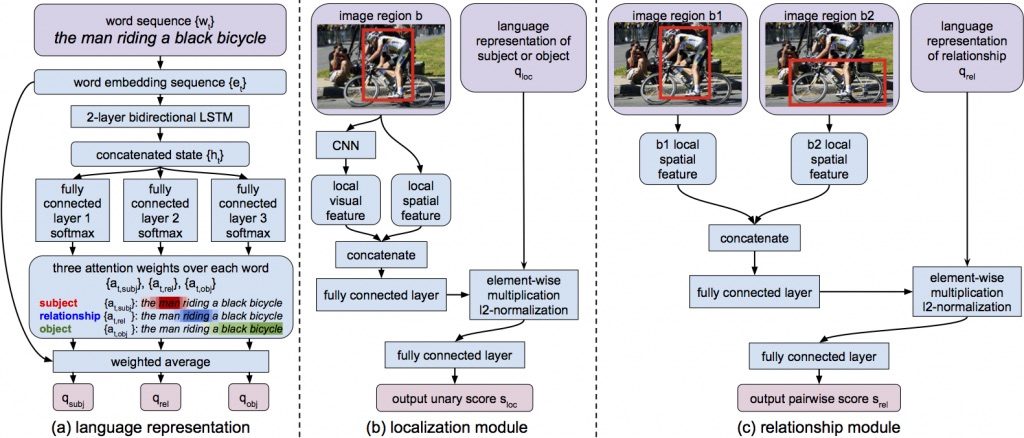
People often refer to entities in an image in terms of their relationships with other entities. For example, "the black cat sitting under the table" refers to both a "black cat" entity and its relationship with another "table" entity. Understanding these relationships is essential for interpreting and grounding such natural language expressions. Most prior work focuses on either grounding entire referential expressions holistically to one region, or localizing relationships based on a fixed set of categories. In this paper we instead present a modular deep architecture capable of analyzing referential expressions into their component parts, identifying entities and relationships mentioned in the input expression and grounding them all in the scene. We call this approach Compositional Modular Networks (CMNs): a novel architecture that learns linguistic analysis and visual inference end-to-end. Our approach is built around two types of neural modules that inspect local regions and pairwise interactions between regions. We evaluate CMNs on multiple referential expression datasets, outperforming state-of-the-art approaches on all tasks.
Publications
- R. Hu, M. Rohrbach, J. Andreas, T. Darrell, K. Saenko, Modeling Relationships in Referential Expressions with Compositional Modular Networks. in CVPR, 2017
(PDF)
@inproceedings{hu2017modeling,
title={Modeling Relationships in Referential Expressions with Compositional Modular Networks},
author={Hu, Ronghang and Rohrbach, Marcus and Andreas, Jacob and Darrell, Trevor and Saenko, Kate},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2017}
}
Code
- Code (in TensorFlow) available at here.